Summary
Wikipedia annotation Edit Wikipedia article
The Rfam group coordinates the annotation of Rfam families in Wikipedia. This family is described by a Wikipedia entry Bglg-cis-reg RNA. More...
This page is based on a Wikipedia article. The text is available under the Creative Commons Attribution/Share-Alike License.
Sequences
Alignment
Seed alignment view
Download
Download a gzip-compressed, Stockholm-format file containing the seed alignment for this family. You may find RALEE useful when viewing sequence alignments.
Submit a new alignment
We're happy receive updated seed alignments for new or existing families. Submit your new alignment and we'll take a look.
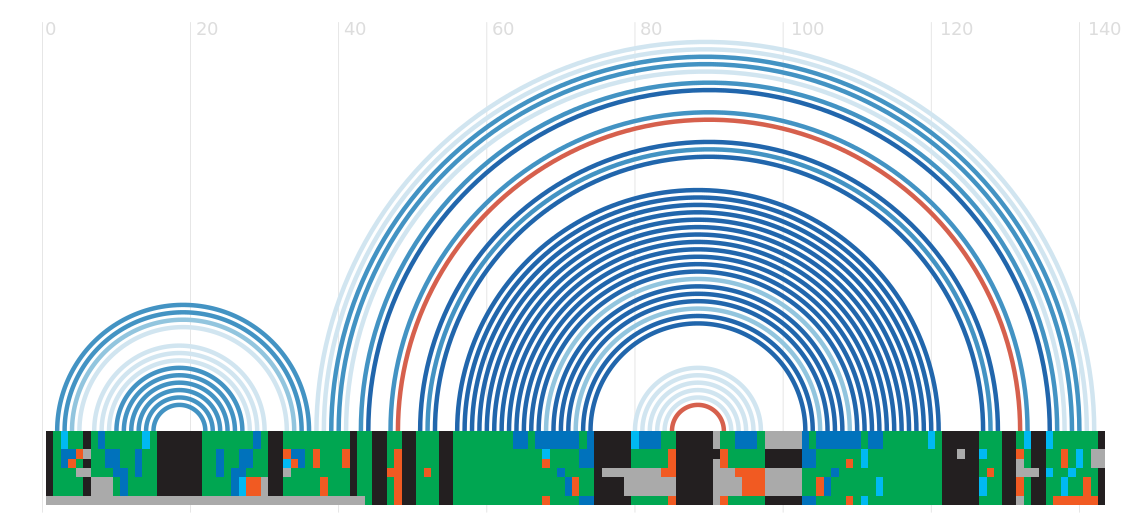
Secondary structure
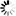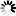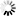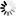 Loading...
Loading...
Species distribution
Sunburst controls
HideWeight segments by...
Change the size of the sunburst
Colour assignments
 Archea
Archea
|
 Eukaryota
Eukaryota
|
 Bacteria
Bacteria
|
 Other sequences
Other sequences
|
 Viruses
Viruses
|
 Unclassified
Unclassified
|
 Viroids
Viroids
|
 Unclassified sequence
Unclassified sequence
|
Selections
Click on a node to select that node and its sub-tree.
Clear selection
This visualisation provides a simple graphical representation of the distribution of this family across species. You can find the original interactive tree in the adjacent tab. More...
Tree controls
HideThe tree shows the occurrence of this RNA across different species. More...
Loading...
Please note: for large trees this can take some time. While the tree is loading, you can safely switch away from this tab but if you browse away from the family page entirely, the tree will not be loaded.
Trees
This page displays the predicted phylogenetic tree for the alignment. More...
Note: You can also download the data file for the seed tree.
Motif matches
There are 2 motifs which match this family.
This section shows the Rfam motifs that match sequences within the seed alignment of this family. Users should be aware that the motifs are structural constructs and do not necessarily conform to taxonomic boundaries in the way that Rfam families do. More...
| Original order | Motif Accession | Motif Description | Number of Hits | Fraction of Hits | Sum of Bits | Image |
|---|---|---|---|---|---|---|
| 7 | RM00022 | Rho independent terminator 1 | 8 | 1.000 | 119.0 |
|
| 7 | RM00023 | Rho independent terminator 2 | 8 | 1.000 | 159.3 |
|
References
This section shows the database cross-references that we have for this Rfam family.
Literature references
-
Soutourina OA, Monot M, Boudry P, Saujet L, Pichon C, Sismeiro O, Semenova E, Severinov K, Le Bouguenec C, Coppee JY, Dupuy B, Martin-Verstraete I PLoS Genet. 2013;9:e1003493. Genome-wide identification of regulatory RNAs in the human pathogen Clostridium difficile. PUBMED:23675309
-
Tanaka Y, Teramoto H, Inui M, Yukawa H J Bacteriol. 2011;193:349-357. Translation efficiency of antiterminator proteins is a determinant for the difference in glucose repression of two beta-glucoside phosphotransferase system gene clusters in Corynebacterium glutamicum R. PUBMED:21075922
External database links
| Sequence Ontology: | SO:0005836 (regulatory_region); |
Curation and family details
This section shows the detailed information about the Rfam family. We're happy to receive updated or improved alignments for new or existing families. Submit your new alignment and we'll take a look.
Curation
| Seed source | PMID:23675309 | ||||||
| Structure source | Predicted; LocaRNA | ||||||
| Type | Cis-reg; | ||||||
| Author |
Secherre E ,
Boudhouche H,
Bahroun R ,
Boudhouche H,
Bahroun R
|
||||||
| Alignment details |
|
Model information
| Build commands |
cmbuild -F CM SEED
cmcalibrate --mpi CM
|
| Search command |
cmsearch --cpu 4 --verbose --nohmmonly -T 30.00 -Z 2958934 CM SEQDB
|
| Gathering cutoff | 80.0 |
| Trusted cutoff | 99.3 |
| Noise cutoff | 78.4 |
| Covariance model | Download |

