Summary
Note on Riboswitches
This Rfam family Guanidine-I (RF00442) represents an aptamer domain of a full riboswitch Guanidine-I riboswitch aptamer. Riboswitches are non-coding RNA structures that regulate gene expression in response to ligand. Each riboswitch has two main parts: the aptamer domain and the expression platform. The aptamer domain is highly conserved to precisely bind its ligand. However, the expression platform has multiple modes of gene regulation, which introduces sequence and structure variability that increases difficulty in its detection through covariance model searching. For more information see the original publications.
Wikipedia annotation Edit Wikipedia article
The Rfam group coordinates the annotation of Rfam families in Wikipedia. This family is described by a Wikipedia entry YkkC-yxkD leader. More...
This page is based on a Wikipedia article. The text is available under the Creative Commons Attribution/Share-Alike License.
Sequences
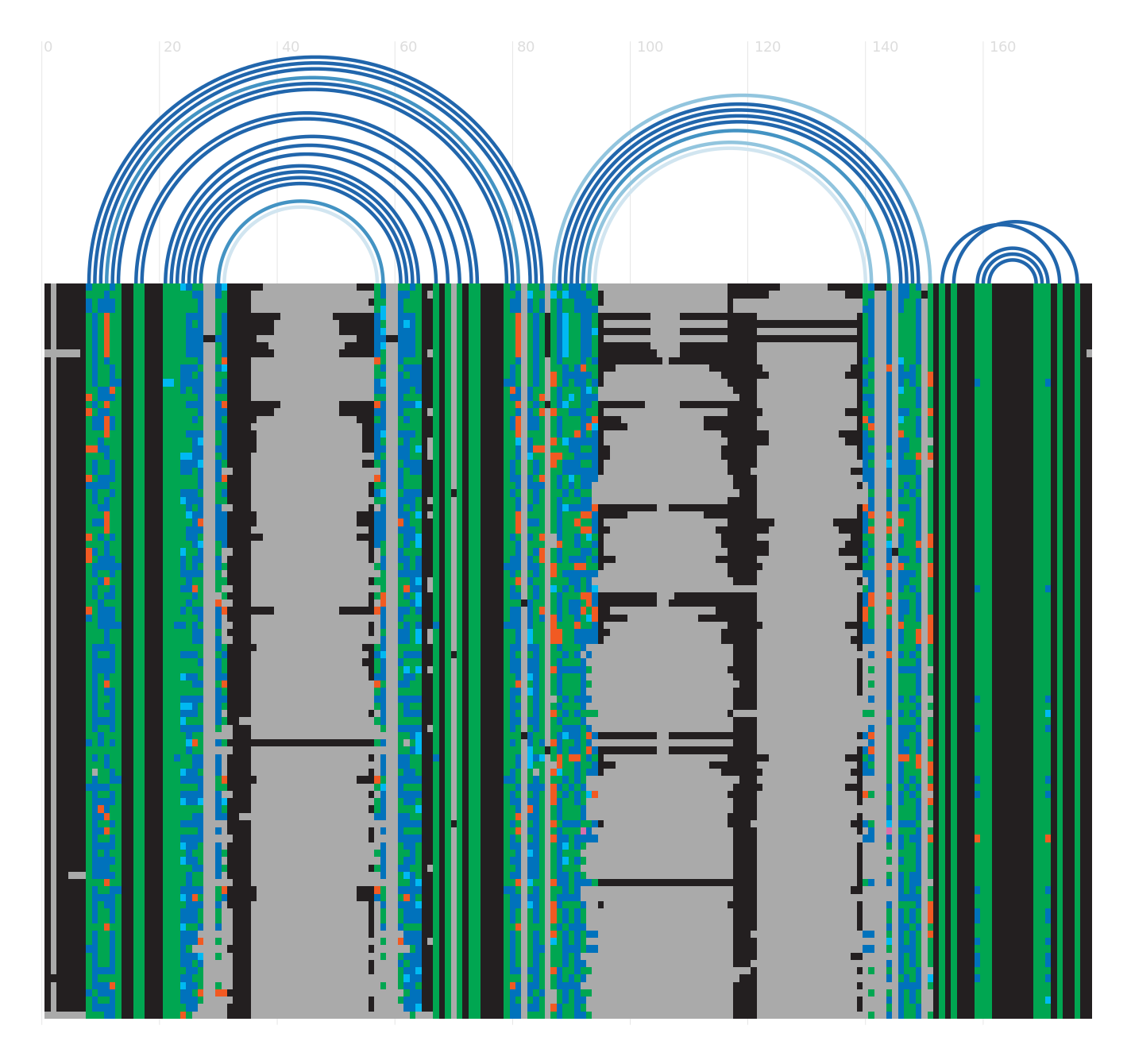
Alignment
Seed alignment view
Download
Download a gzip-compressed, Stockholm-format file containing the seed alignment for this family. You may find RALEE useful when viewing sequence alignments.
Submit a new alignment
We're happy receive updated seed alignments for new or existing families. Submit your new alignment and we'll take a look.
Secondary structure
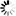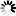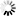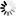 Loading...
Loading...
Species distribution
Sunburst controls
HideWeight segments by...
Change the size of the sunburst
Colour assignments
 Archea
Archea
|
 Eukaryota
Eukaryota
|
 Bacteria
Bacteria
|
 Other sequences
Other sequences
|
 Viruses
Viruses
|
 Unclassified
Unclassified
|
 Viroids
Viroids
|
 Unclassified sequence
Unclassified sequence
|
Selections
Click on a node to select that node and its sub-tree.
Clear selection
This visualisation provides a simple graphical representation of the distribution of this family across species. You can find the original interactive tree in the adjacent tab. More...
Tree controls
HideThe tree shows the occurrence of this RNA across different species. More...
Loading...
Please note: for large trees this can take some time. While the tree is loading, you can safely switch away from this tab but if you browse away from the family page entirely, the tree will not be loaded.
Trees
This page displays the predicted phylogenetic tree for the alignment. More...
Note: You can also download the data file for the seed tree.
Structures
For those sequences which have a structure in the Protein DataBank, we generate a mapping between EMBL, PDB and Rfam coordinate systems. The table below shows the structures on which the Guanidine-I family has been found.
Loading structure mapping...
Motif matches
There are 3 motifs which match this family.
This section shows the Rfam motifs that match sequences within the seed alignment of this family. Users should be aware that the motifs are structural constructs and do not necessarily conform to taxonomic boundaries in the way that Rfam families do. More...
| Original order | Motif Accession | Motif Description | Number of Hits | Fraction of Hits | Sum of Bits | Image |
|---|---|---|---|---|---|---|
| 7 | RM00005 | CsrA/RsmA binding motif | 11 | 0.110 | 102.8 |
|
| 7 | RM00008 | GNRA tetraloop | 24 | 0.240 | 297.2 |
|
| 7 | RM00030 | U-turn motif | 10 | 0.100 | 143.8 |
|
References
This section shows the database cross-references that we have for this Rfam family.
Literature references
-
Barrick JE, Corbino KA, Winkler WC, Nahvi A, Mandal M, Collins J, Lee M, Roth A, Sudarsan N, Jona I, Wickiser JK, Breaker RR Proc Natl Acad Sci U S A 2004;101:6421-6426. New RNA motifs suggest an expanded scope for riboswitches in bacterial genetic control. PUBMED:15096624
-
Nelson JW, Atilho RM, Sherlock ME, Stockbridge RB, Breaker RR Mol Cell. 2017;65:220-230. Metabolism of Free Guanidine in Bacteria Is Regulated by a Widespread Riboswitch Class. PUBMED:27989440
-
Battaglia RA, Price IR, Ke A RNA. 2017;23:578-585. Structural basis for guanidine sensing by the ykkC family of riboswitches. PUBMED:28096518
-
Reiss CW, Xiong Y, Strobel SA Structure. 2017;25:195-202. Structural Basis for Ligand Binding to the Guanidine-I Riboswitch. PUBMED:28017522
-
Trachman RJ 3rd, Ferre-D'Amare AR RNA. 2021;27:1257-1264. An uncommon [K(+)(Mg(2+))2] metal ion triad imparts stability and selectivity to the Guanidine-I riboswitch. PUBMED:34257148
External database links
| Gene Ontology: | GO:0010468 (regulation of gene expression); |
| Sequence Ontology: | SO:0000035 (riboswitch); |
Curation and family details
This section shows the detailed information about the Rfam family. We're happy to receive updated or improved alignments for new or existing families. Submit your new alignment and we'll take a look.
Curation
| Seed source | Barrick JE, Breaker RR | ||||||
| Structure source | Predicted; Barrick JE, Breaker RR | ||||||
| Type | Cis-reg; riboswitch; | ||||||
| Author |
Moxon SJ ,
Ontiveros-Palacios N ,
Ontiveros-Palacios N
|
||||||
| Alignment details |
|
Model information
| Build commands |
cmbuild -F CM SEED
cmcalibrate --mpi CM
|
| Search command |
cmsearch --cpu 4 --verbose --nohmmonly -T 30.00 -Z 2958934 CM SEQDB
|
| Gathering cutoff | 63.0 |
| Trusted cutoff | 63.0 |
| Noise cutoff | 62.9 |
| Covariance model | Download |

